이진 검색 트리에(BST) 는 모든 노드를 따라 아래에 언급 속성−
-
키의 값의 왼쪽 하위 트리보다 작은 값의 상위(root)노드의 열쇠이다.
-
오른쪽 하위 트리의 키 값은 부모(루트)노드의 키 값보다 크거나 같습니다.,
따라서,BST 나누는 모든 서브 나무 두 개의 세그먼트로 왼쪽의 서브 나무와 권위는 나무로 정의할 수 있습−
left_subtree (keys) < node (key) ≤ right_subtree (keys)
표현
영국 서머 타임이션 노드의 배열되는 방법에 있는 그들은 유지 BST 속성입니다. 각 노드에는 키와 연관된 값이 있습니다. 검색하는 동안 원하는 키가 BST 의 키와 비교되고 발견되면 관련 값이 검색됩니다.,
다음의 그림 표현 BST−
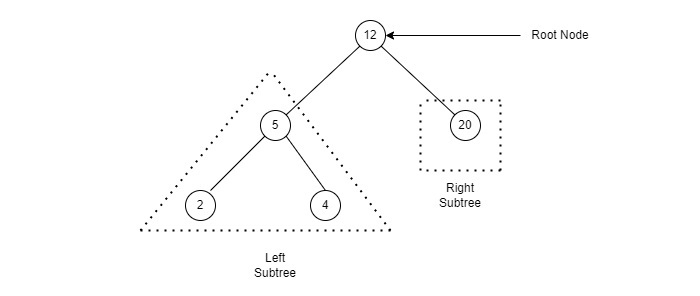
우리가 관찰하는 루트 노드를 키(27)는 모든 더 적은 반환 키에 왼쪽 하위 나무 및 높은 가치에 sub-나무입니다.
기본 연산
다음은 트리의 기본 연산입니다.
-
Search−트리의 요소를 검색합니다.
-
삽입-트리에 요소를 삽입합니다.
-
선주문 순회−선주문 방식으로 트리를 순회합니다.
-
In-order Traversal−in-order 방식으로 트리를 순회합니다.,
-
주문 후 순회-주문 후 방식으로 트리를 순회합니다.
노드
정의 노드하는 데 어떤 데이터에 대한 참조는 그것의 왼쪽과 오른쪽 아동 노드입니다.
struct node { int data; struct node *leftChild; struct node *rightChild;};
검색 조작
때마다 요소를 검색에서 검색을 시작합니다 그런 다음 데이터가 키 값보다 작 으면 왼쪽 하위 트리에서 요소를 검색하십시오. 그렇지 않으면 오른쪽 하위 트리에서 요소를 검색하십시오. 각 노드에 대해 동일한 알고리즘을 따르십시오.,
알고리즘
삽입 작업
때마다 요소를 삽입되는,먼저 찾는 적절한 위치에 있습니다. 검색을 시작하는 루트 노드에서 다음 경우,데이터보다 작은 키 값 검색,빈에 위치 왼쪽 하위트리고 삽입하는 데이터입니다. 그렇지 않으면 오른쪽 하위 트리에서 빈 위치를 검색하고 데이터를 삽입하십시오.